Skip to content
GitLab
Projects
Groups
Snippets
Help
Loading...
Help
Help
Support
Keyboard shortcuts
?
Submit feedback
Sign in
Toggle navigation
2
2022fall-Compiler_CMinus
Project overview
Project overview
Details
Activity
Releases
Repository
Repository
Files
Commits
Branches
Tags
Contributors
Graph
Compare
Issues
0
Issues
0
List
Boards
Labels
Service Desk
Milestones
Merge Requests
6
Merge Requests
6
CI / CD
CI / CD
Pipelines
Jobs
Schedules
Operations
Operations
Metrics
Analytics
Analytics
CI / CD
Repository
Value Stream
Wiki
Wiki
Snippets
Snippets
Members
Members
Collapse sidebar
Close sidebar
Activity
Graph
Create a new issue
Jobs
Commits
Issue Boards
Open sidebar
李晓奇
2022fall-Compiler_CMinus
Commits
689749e4
Commit
689749e4
authored
Mar 05, 2023
by
lxq
Browse files
Options
Browse Files
Download
Email Patches
Plain Diff
report
parent
11042e7a
Changes
10
Show whitespace changes
Inline
Side-by-side
Showing
10 changed files
with
237 additions
and
66 deletions
+237
-66
Reports/5-bonus/.gitignore
Reports/5-bonus/.gitignore
+1
-0
Reports/5-bonus/figures/5-while_aft.png
Reports/5-bonus/figures/5-while_aft.png
+0
-0
Reports/5-bonus/figures/5-while_bef.png
Reports/5-bonus/figures/5-while_bef.png
+0
-0
Reports/5-bonus/figures/5-while_final.png
Reports/5-bonus/figures/5-while_final.png
+0
-0
Reports/5-bonus/figures/pass.png
Reports/5-bonus/figures/pass.png
+0
-0
Reports/5-bonus/figures/simpleloop.png
Reports/5-bonus/figures/simpleloop.png
+0
-0
Reports/5-bonus/report.md
Reports/5-bonus/report.md
+193
-38
src/cminusfc/cminusfc.cpp
src/cminusfc/cminusfc.cpp
+4
-4
src/optimization/BrMerge.cpp
src/optimization/BrMerge.cpp
+39
-21
src/optimization/LoopUnroll.cpp
src/optimization/LoopUnroll.cpp
+0
-3
No files found.
Reports/5-bonus/.gitignore
0 → 100644
View file @
689749e4
report.pdf
Reports/5-bonus/figures/5-while_aft.png
0 → 100644
View file @
689749e4
128 KB
Reports/5-bonus/figures/5-while_bef.png
0 → 100644
View file @
689749e4
43.7 KB
Reports/5-bonus/figures/5-while_final.png
0 → 100644
View file @
689749e4
18.7 KB
Reports/5-bonus/figures/pass.png
0 → 100644
View file @
689749e4
107 KB
Reports/5-bonus/figures/simpleloop.png
0 → 100644
View file @
689749e4
1.51 MB
Reports/5-bonus/report.md
View file @
689749e4
# Lab5 报告
# Lab5 报告
[TOC]
## 实验任务
## 实验任务
基于前4个实验,完成对LightIR的翻译,目标架构为龙芯LA64架构。
基于前4个实验,完成对LightIR的翻译,目标架构为龙芯LA64架构。
## 实验结果
以下均使用参数
`-mem2reg -gvn -loopunroll`
。
### 1. 正确性
功能正确性由以下测试样例作为证明:
-
`tests/5-bonus/testcases`
-
`tests/3-ir-gen/testcases`
> lab3修改后的测试脚本见[GitLab](https://cscourse.ustc.edu.cn/vdir/Gitlab/PB20111654/2022fall-compiler_cminus/-/blob/master/tests/3-ir-gen/eval_lab5.py)(助教应该能看见)
### 2. 性能
极简测试样例与clang存在差距,复杂样例似乎还要略优一些?
-
`tests/5-bonus/testcases`
在上午十点测试,cminusfc和clang均跑三次,取平均值:
| | avg total time | avg avg time |
| -------- | -------------- | ------------ |
| cminusfc | 0.0275s | 0.00212s |
| clang | 0.0249s | 0.00192s |
-
`tests/4-ir-opt/testcases/GVN/performance/const-prop.cminus`
`IN`
是输入文件,
`a.out`
和
`test`
分别是clang和cminusfc生成的可执行文件,下同。
```
shell
[
PB20111654@localhost
test
]
$
time cat
IN | ./a.out
711082625
real 0m4.997s
user 0m4.998s
sys 0m0.000s
[
PB20111654@localhost
test
]
$
time cat
IN | ./test
711082625
real 0m0.138s
user 0m0.138s
sys 0m0.000s
```
-
`tests/4-ir-opt/testcases/GVN/performance/transpose.cminus`
```
shell
[
PB20111654@localhost
test
]
$
time cat
IN | ./a.out
1042523985
real 0m3.024s
user 0m3.012s
sys 0m0.013s
[
PB20111654@localhost
test
]
$
time cat
IN | ./test
1042523985
real 0m2.954s
user 0m2.938s
sys 0m0.017s
```
## 实验流程
## 实验流程
#### 1. 使用栈式内存分配,优先追求功能性
### 1. 栈式内存分配,优先追求功能性
首先使用栈式内存分配,追求功能性。
这一步主要完成了指令选择,所有变量(local
or
global)均在栈中储存,参数通过栈传递。常量保存在只读区(模拟gcc)。
这一步主要完成了指令选择,所有变量(local
&
global)均在栈中储存,参数通过栈传递。常量保存在只读区(模拟gcc)。
这里对于phi指令的处理是:将phi指令还原为前驱块的
`copy-statement`
,需要将其插入在基本块的最后一条指令(跳转指令)之前。
这里对于phi指令的处理是:将phi指令还原为前驱块的
`copy-statement`
,需要将其插入在基本块的最后一条指令(跳转指令)之前。
...
@@ -16,9 +83,15 @@
...
@@ -16,9 +83,15 @@
这一步可以完成所有测试样例,但是生成的代码效率较差。
这一步可以完成所有测试样例,但是生成的代码效率较差。
###
# 2. 活跃变量分析
###
2. 寄存器分配
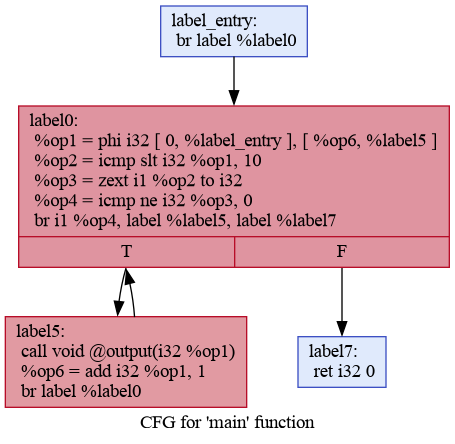
先确定指令的遍历顺序,这里使用常规的BFS遍历,phi指令的处理和上述相同,例如对于
`5-while.ll`
:
寄存器分配采用线性扫描算法,对于整数使用15个寄存器,浮点数使用22个寄存器,分别保留两个寄存器作为临时寄存器。线性扫描之前需要进行活跃变量分析
#### 1)活跃变量分析
采用数据流方法进行活跃变量分析,得到每个变量的活跃区间。
先确定指令的遍历顺序,这里使用DFS顺序,phi指令的处理和栈式分配相同,例如对于
`5-while.ll`
:
```
llvm
```
llvm
define
i32
@main
()
{
define
i32
@main
()
{
...
@@ -42,6 +115,7 @@ label7: ; preds = %label0
...
@@ -42,6 +115,7 @@ label7: ; preds = %label0
指令遍历顺序如下,第1条与第9条指令就是phi指令的还原。
指令遍历顺序如下,第1条与第9条指令就是phi指令的还原。
```
llvm
```
llvm
0
.
Entry
1
.
op1
=
0
1
.
op1
=
0
2
.
br
label
%label0
2
.
br
label
%label0
3
.
%op2
=
icmp
slt
i32
%op1
,
10
3
.
%op2
=
icmp
slt
i32
%op1
,
10
...
@@ -58,6 +132,9 @@ label7: ; preds = %label0
...
@@ -58,6 +132,9 @@ label7: ; preds = %label0
用编号代替指令,获得每个程序点的IN和OUT:
用编号代替指令,获得每个程序点的IN和OUT:
```
llvm
```
llvm
0
.
Entry
in-set:
[
]
out-set:
[
]
1
.
op1
=
0
1
.
op1
=
0
in-set:
[
]
in-set:
[
]
out-set:
[
op1
]
out-set:
[
op1
]
...
@@ -93,17 +170,19 @@ label7: ; preds = %label0
...
@@ -93,17 +170,19 @@ label7: ; preds = %label0
out-set:
[
]
out-set:
[
]
```
```
获得活跃区间:编号为i的指令,涉及两个端点:i
-1和i
,分别对应IN和OUT。由此得到各个变量的活跃区间是:
获得活跃区间:编号为i的指令,涉及两个端点:i
和i+1
,分别对应IN和OUT。由此得到各个变量的活跃区间是:
```
llvm
```
llvm
op1:
<
1
,
10
>
op1:
<
2
,
11
>
op2:
<
3
,
3
>
op2:
<
4
,
4
>
op3:
<
4
,
4
>
op3:
<
5
,
5
>
op4:
<
5
,
5
>
op4:
<
6
,
6
>
op6:
<
8
,
8
>
op6:
<
9
,
9
>
```
```
#### 3. 寄存器分配
除了常规的数据流外,还要手动将实参加入IN[ENTRY]中,以保证正确。
#### 2)寄存器分配
使用线性扫描算法实现寄存器分配,参考:
使用线性扫描算法实现寄存器分配,参考:
...
@@ -111,13 +190,15 @@ op6: <8, 8>
...
@@ -111,13 +190,15 @@ op6: <8, 8>
-
[
Documentations/5-bonus/寄存器分配.md · master · compiler_staff / 2022fall-Compiler_CMinus · GitLab
](
https://cscourse.ustc.edu.cn/vdir/Gitlab/compiler_staff/2022fall-compiler_cminus/-/blob/master/Documentations/5-bonus/%E5%AF%84%E5%AD%98%E5%99%A8%E5%88%86%E9%85%8D.md#poletto
)
-
[
Documentations/5-bonus/寄存器分配.md · master · compiler_staff / 2022fall-Compiler_CMinus · GitLab
](
https://cscourse.ustc.edu.cn/vdir/Gitlab/compiler_staff/2022fall-compiler_cminus/-/blob/master/Documentations/5-bonus/%E5%AF%84%E5%AD%98%E5%99%A8%E5%88%86%E9%85%8D.md#poletto
)
这里以整形寄存器为例介绍该部分的实现。
程序有
`$a`
系列寄存器8个,
`$t`
系列9个,拿出
`$t0`
、
`$t1`
做IR生成汇编过程中的临时寄存器(这个方案仅在cminus下成立),所以可以自由分配的寄存器一共15个。
程序有
`$a`
系列寄存器8个,
`$t`
系列9个,拿出
`$t0`
、
`$t1`
做IR生成汇编过程中的临时寄存器(这个方案仅在cminus下成立),所以可以自由分配的寄存器一共15个。
首先完成对于局部变量和参数的整形寄存器分配。
首先完成对于局部变量和参数的整形寄存器分配。
程序分配寄存器时会对部分指令做特殊处理,具体如下:
程序分配寄存器时会对部分指令做特殊处理,具体如下:
-
`phi`
指令:还原
为
`copy-stmt`
,所以寄存器照样分配,如果没分到使用栈内存
-
`phi`
指令:还原
的两个
`copy-stmt`
是同一个定值,所以分配一个寄存器。
-
`alloca`
指令:这里忽略对于
`alloca`
指令的寄存器分配,
`alloca`
仍然使用栈存储,原因如下:
-
`alloca`
指令:这里忽略对于
`alloca`
指令的寄存器分配,
`alloca`
仍然使用栈存储,原因如下:
...
@@ -135,36 +216,110 @@ op6: <8, 8>
...
@@ -135,36 +216,110 @@ op6: <8, 8>
一个例外是隐式的类型转化,将比较的结果
`i1`
隐式转换为
`i32`
,此时是
`zext`
指令与
`cmp`
捆绑,特殊为
`zext`
指令分配寄存器。
一个例外是隐式的类型转化,将比较的结果
`i1`
隐式转换为
`i32`
,此时是
`zext`
指令与
`cmp`
捆绑,特殊为
`zext`
指令分配寄存器。
-
`call`
指令:
使用栈传参,caller保存自己用到的寄存器,被保存的寄存器的活跃区间
覆盖
`call`
指令的程序点。
-
`call`
指令:
前八个参数使用寄存器传参,此后使用栈。caller保存自己用到的寄存器:被保存寄存器的活跃区间要
覆盖
`call`
指令的程序点。
参数传递:固定为前8个参数分配
`$a0`
\~
`$a7`
,超过8个使用栈传递。
## 优化
###
# 4. 局部
优化
###
1. 指令选择的
优化
-
基于跳转的bool变量翻译
。
-
基于跳转的bool变量翻译
-
GEP取值的优化:两个0的情况
cminus中没有bool变量,对应的IR中所有
`i1`
类型都是类型转换时临时使用,其出现都是和其他比较指令捆绑在一起
```
llvm
1
.
%op3
=
icmp
slt
i32
%op2
,
10
2
.
%op4
=
zext
i1
%op3
to
i32
3
.
%op5
=
icmp
ne
i32
%op4
,
0
4
.
br
i1
%op5
,
label
%label6
,
label
%label11
```
常见的是1
\~
4(
`while(i<10)`
)的捆绑,和3
\~
4的捆绑(
`while(i)`
)
还有隐式类型转换(
`a=b<c`
)
对于第一种情况可以将bool变量整合进跳转指令中,如上1
\~
4仅需两个汇编指令:
```
python
# %op2 = phi i32 [ 0, %label_entry ], [ %op10, %label6 ]
# %op3 = icmp slt i32 %op2, 10
# %op4 = zext i1 %op3 to i32
# %op5 = icmp ne i32 %op4, 0
# br i1 %op5, label %label6, label %label11
blt
$
a2
,
$
t1
,
main6
# ¥
b
main11
```
-
GEP的优化
经常出现类似GEP偏移量均为
`%op7 = getelementptr [10 x i32], [10 x i32]* %op0, i32 0, i32 0
`
这种只需提取基地址即可。
-
常量取值的优化
-
常量取值的优化
-
对于整数,可以使用
`or dest, $r0, imm`
完成,1条指令,范围[-2048, 2047]。也可以通过内存提取,需要提取地址+读内存,2条指令。所以允许时,使用立即数表示,可以节约一条指令。
###
# 5. 测试样例
###
2. 循环展开
功能正确性由以下几部分测试样例作为证明
:
使用前
:
-
`/tests/5-bonus/testcases`
<img
src=
"figures/5-while_bef.png"
title=
""
alt=
""
width=
"345"
>
-
`tests/3-ir-gen/testcases`
使用后:
<img
src=
"figures/5-while_aft.png"
title=
""
alt=
""
width=
"190"
>
然后配合常量传播与死代码消除,得到最终的结果:

在汇编层面,这个优化可以减少分支、利用常量传播消除归纳变量、减少函数调用时的caller save等。
其实现分为以下几个点:
-
`neg_idx_except`
块的合并:将同一个函数内对于
`neg_idx_except()`
的调用块合并为一个,方便后续判断,也减少了代码空间。
-
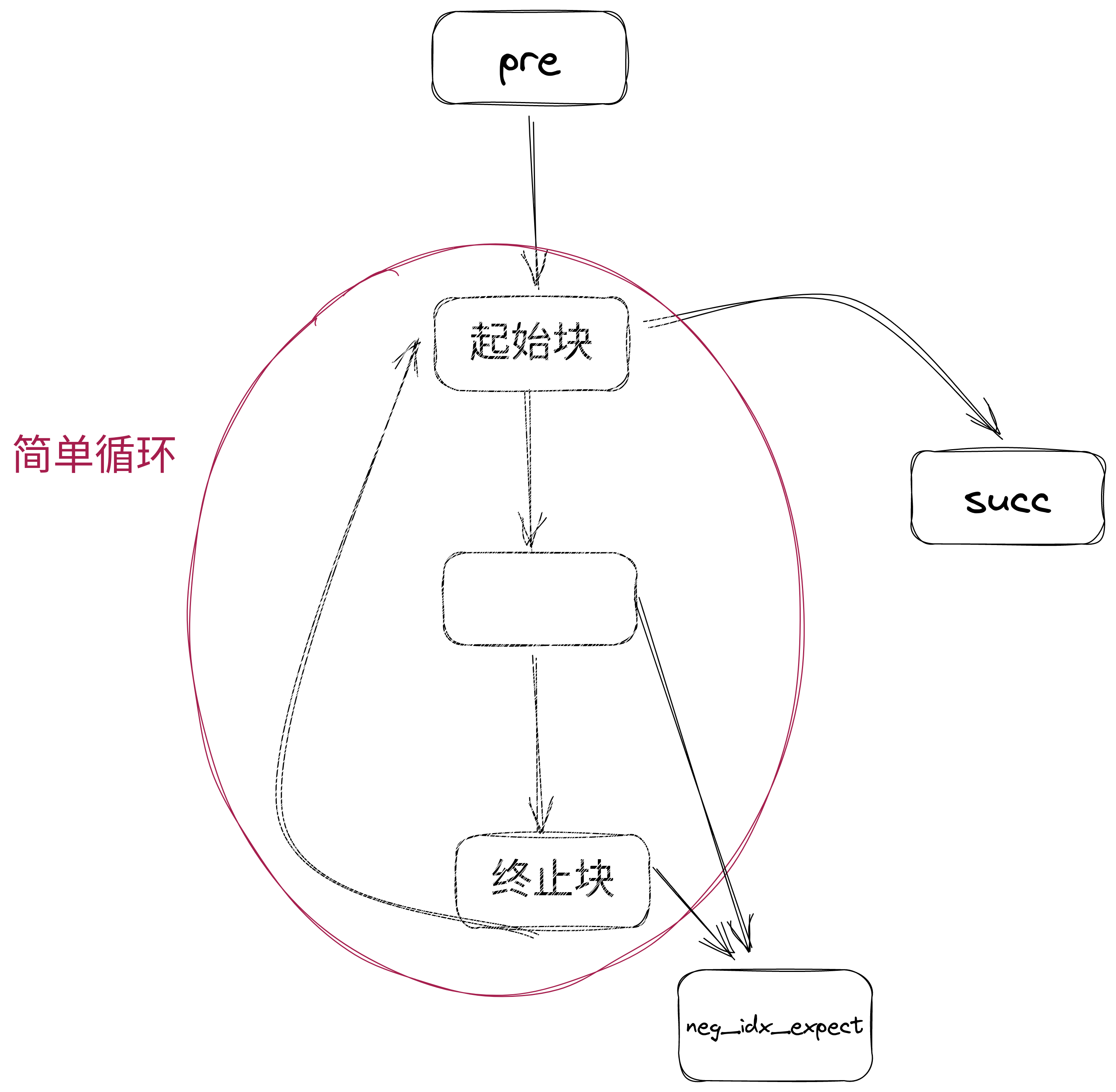
检测简单循环:根据DFS过程中的回边判断循环,仅针对简单循环尝试展开,简单循环的结构如下,核心在于循环内除了起始块都只有唯一出边,例外是对于
`neg_idx_except()`
的调用。
!
[](
figures/simpleloop.png
)
-
循环分析:检测循环次数,如果在一定阈值内就进行展开,比较琐碎的是维护基本块的前后关系、维护uselist等。
## 正确性
这里仅挑选比较废脑筋的两个问题进行阐述。
### 1. 参数传递
参数传递过程中,可能出现循环依赖的问题,最简单的示例是:
`func(a, b)`
,此时a、b的值分别保存在
`$a1`
、
`$a0`
中,为了正确赋值,需要使用临时寄存器保存其中一个值,打破循环依赖。由此,也不可简单按顺序传递参数,譬如a、b的值分别在
`$t0`
、
`$a0`
时,如果先传递a的值,就会丢失b的真实值,而按照b、a的顺序赋值,则不会出现任何问题。
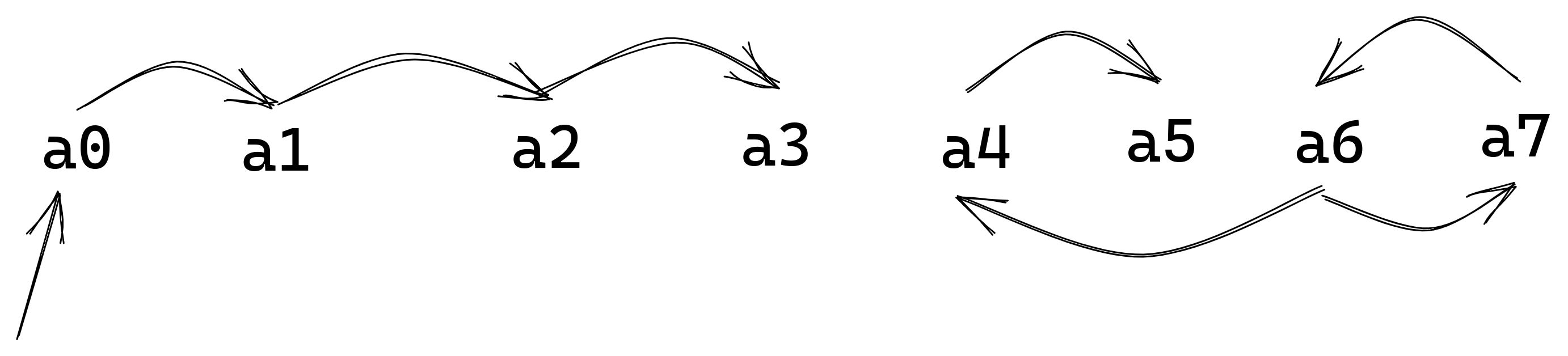
这个问题本质上是要得到参数赋值的正确顺序,同时维护一个临时寄存器的信息。由于一个参数有且仅有一个赋值,所以在依赖图(下面介绍)上,每个节点有且只有一条入边,由此一个节点最多位于一个圈上。所以只需要一个临时寄存器就可以完成参数传递的工作。
依赖图的上有8个节点,分别代表
`$a0`
\~
`$a7`
,边i->j表示传递参数时,寄存器的j的值来源是i,因为寄存器的值也可能来自于
`$a0`
\~
`$a7`
之外的寄存器,所以存在无源节点的边。
例如:

对于这个依赖图,一个可靠的赋值顺序是:
a3, a2, a1, a0, a5, a4, a6, a7
对a6赋值时,要先保存a6的值到t中,然后用t对a7赋值。
借鉴拓扑排序+贪心的思想实现,代码在
`src/codegen/codegen.cpp:CodeGen::pass_arguments`
。
### 2. caller save
如果一个变量的活跃区间覆盖了一条call指令,在call被调用前需要备份其值。
而性能主要向gcc看齐,主要测试样例为
如果call指令刚好在其活跃区间的边界,则需要慎重考虑。假设活跃区间左右端点分别为i、j,call指令的编号为c,根据自定的编号规则,call指令的IN和ENTRY分别对应c和c+1。
-
`tests/4-ir-opt/testcases/GVN/performance`
-
如果i==j,变量仅在一点活跃,不需要保存
## 局限性
-
如果i==c,检查call指令的IN集合,仅包含该变量时做备份。因为编号不能体现图结构,可能存在情况:call的上一条指令是分支点,恰好call排列在分支点之下,导致分支点的OUT和call的IN重合。
-
GEP的取巧设计
-
如果j==c,该变量对call及以后指令的唯一可能作用:为call指令传递参数。所以无需备份。
-
未考虑指令寻址的立即数
## 总结
-
本次实验体验不错,有学习到更多知识,对编译器也有了更深了解,辛苦老师和助教的付出~
src/cminusfc/cminusfc.cpp
View file @
689749e4
...
@@ -127,10 +127,10 @@ main(int argc, char **argv) {
...
@@ -127,10 +127,10 @@ main(int argc, char **argv) {
if
(
loopunroll
)
{
if
(
loopunroll
)
{
PM
.
add_pass
<
NegCallMerge
>
(
false
);
PM
.
add_pass
<
NegCallMerge
>
(
false
);
PM
.
add_pass
<
LoopUnroll
>
(
false
);
PM
.
add_pass
<
LoopUnroll
>
(
false
);
PM
.
add_pass
<
DeadCode
>
(
false
);
/*
PM.add_pass<DeadCode>(false);
PM
.
add_pass
<
GVN
>
(
false
,
dump_json
);
*
PM.add_pass<GVN>(false, dump_json);
PM
.
add_pass
<
DeadCode
>
(
false
);
* PM.add_pass<DeadCode>(false); */
PM
.
add_pass
<
BrMerge
>
(
false
);
//
PM.add_pass<BrMerge>(false);
}
}
PM
.
run
();
PM
.
run
();
...
...
src/optimization/BrMerge.cpp
View file @
689749e4
...
@@ -4,15 +4,23 @@
...
@@ -4,15 +4,23 @@
#include "Constant.h"
#include "Constant.h"
#include "Instruction.h"
#include "Instruction.h"
#include <iostream>
using
std
::
cout
;
using
std
::
endl
;
void
void
BrMerge
::
run
()
{
BrMerge
::
run
()
{
m_
->
set_print_name
();
BranchInst
*
br
;
BranchInst
*
br
;
ReturnInst
*
ret
;
ReturnInst
*
ret
;
for
(
auto
&
func
:
m_
->
get_functions
())
{
for
(
auto
&
func
:
m_
->
get_functions
())
{
if
(
func
.
is_declaration
())
continue
;
bool
cont
=
true
;
bool
cont
=
true
;
while
(
cont
)
{
while
(
cont
)
{
cont
=
false
;
cont
=
false
;
for
(
auto
&
bb
:
func
.
get_basic_blocks
())
{
for
(
auto
&
bb
:
func
.
get_basic_blocks
())
{
cout
<<
bb
.
get_name
()
<<
endl
;
if
(
&
bb
==
func
.
get_entry_block
())
if
(
&
bb
==
func
.
get_entry_block
())
continue
;
continue
;
auto
&
instructions
=
bb
.
get_instructions
();
auto
&
instructions
=
bb
.
get_instructions
();
...
@@ -28,14 +36,21 @@ BrMerge::run() {
...
@@ -28,14 +36,21 @@ BrMerge::run() {
}
else
if
(
dynamic_cast
<
Constant
*>
(
}
else
if
(
dynamic_cast
<
Constant
*>
(
br
->
get_operand
(
0
)))
{
br
->
get_operand
(
0
)))
{
assert
(
bb
.
get_succ_basic_blocks
().
size
()
==
2
);
assert
(
bb
.
get_succ_basic_blocks
().
size
()
==
2
);
succ
=
static_cast
<
BasicBlock
*>
(
auto
const_bool
=
dynamic_cast
<
ConstantInt
*>
(
br
->
get_operand
(
0
))
dynamic_cast
<
ConstantInt
*>
(
br
->
get_operand
(
0
))
->
get_value
()
->
get_value
();
?
br
->
get_operand
(
1
)
succ
=
static_cast
<
BasicBlock
*>
(
const_bool
?
br
->
get_operand
(
1
)
:
br
->
get_operand
(
2
));
:
br
->
get_operand
(
2
));
static_cast
<
BasicBlock
*>
(
(
const_bool
?
br
->
get_operand
(
2
)
:
br
->
get_operand
(
1
)))
->
remove_pre_basic_block
(
&
bb
);
}
else
}
else
continue
;
continue
;
for
(
auto
pre
:
bb
.
get_pre_basic_blocks
())
{
if
(
bb
.
get_pre_basic_blocks
().
size
()
!=
1
)
continue
;
auto
pre
=
*
bb
.
get_pre_basic_blocks
().
begin
();
// change br's op
// change br's op
auto
ins
=
&*
pre
->
get_instructions
().
rbegin
();
auto
ins
=
&*
pre
->
get_instructions
().
rbegin
();
bool
set
=
false
;
bool
set
=
false
;
...
@@ -43,6 +58,7 @@ BrMerge::run() {
...
@@ -43,6 +58,7 @@ BrMerge::run() {
if
(
ins
->
get_operand
(
i
)
==
&
bb
)
{
if
(
ins
->
get_operand
(
i
)
==
&
bb
)
{
ins
->
set_operand
(
i
,
succ
);
ins
->
set_operand
(
i
,
succ
);
set
=
true
;
set
=
true
;
bb
.
remove_use
(
ins
);
break
;
break
;
}
}
assert
(
set
);
assert
(
set
);
...
@@ -51,12 +67,14 @@ BrMerge::run() {
...
@@ -51,12 +67,14 @@ BrMerge::run() {
pre
->
add_succ_basic_block
(
&
bb
);
pre
->
add_succ_basic_block
(
&
bb
);
// change succ's pre
// change succ's pre
succ
->
add_pre_basic_block
(
pre
);
succ
->
add_pre_basic_block
(
pre
);
}
// change succ's pre
// change succ's pre
succ
->
remove_pre_basic_block
(
&
bb
);
succ
->
remove_pre_basic_block
(
&
bb
);
// remove useless block
// remove useless block
func
.
get_basic_blocks
().
remove
(
&
bb
);
func
.
get_basic_blocks
().
remove
(
&
bb
);
// replace use
bb
.
replace_all_use_with
(
pre
);
cont
=
true
;
cont
=
true
;
break
;
}
else
{
// ret: do not change
}
else
{
// ret: do not change
}
}
}
else
{
}
else
{
...
...
src/optimization/LoopUnroll.cpp
View file @
689749e4
...
@@ -128,9 +128,6 @@ LoopUnroll::unroll_loop(SimpleLoop &sl) {
...
@@ -128,9 +128,6 @@ LoopUnroll::unroll_loop(SimpleLoop &sl) {
// neg block's pre blocks
// neg block's pre blocks
// replace use
// replace use
m_
->
set_print_name
();
for
(
auto
[
k
,
v
]
:
old2new
)
cout
<<
"[debug]"
<<
k
->
get_name
()
<<
"-"
<<
v
->
get_name
()
<<
endl
;
for
(
auto
&
bb
:
func
->
get_basic_blocks
())
{
for
(
auto
&
bb
:
func
->
get_basic_blocks
())
{
for
(
auto
&
instr
:
bb
.
get_instructions
())
{
for
(
auto
&
instr
:
bb
.
get_instructions
())
{
for
(
int
i
=
0
;
i
<
instr
.
get_num_operand
();
++
i
)
{
for
(
int
i
=
0
;
i
<
instr
.
get_num_operand
();
++
i
)
{
...
...
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}

{kind=link}
{kind=link}

{kind=link}
{kind=link}